

SDS(Simple Dynamic String)
注:基于redis版本6.0
SDS是Redis提供的字符串的封装。SDS也兼容部分C字符串API(strcmp,strlen)
1.C语言中也算支持String了,为什么Redis还要自己封装一个?
2.SDS的数据结构是啥样的?为什么这样设计?
3.SDS是如何兼容C字符串的?
一 sdshdr数据结构
Redis提供了sdshdr5,sdshdr8,sdshdr16,sdshdr32,sdshdr64这几种sds的实现.其中处理sdshdr比较特殊意外,其他几种sdshdr差不只在于字段类型差别,以sdshdr8和sdshdr16举例,源码:
struct __attribute__ ((__packed__)) sdshdr5 {
/* 实际上这个类型redis不会被使用。他的内部结构也与其他sdshdr不同,直接看sdshdr8就好。*/
unsigned char flags; /* 3 lsb of type, and 5 msb of string length *//* 一共8位,低3位用来存放真实的flags(类型),高5位用来存放len(长度)。*/
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used *//*表示当前sds的长度(单位是字节)*/
uint8_t alloc; /* excluding the header and null terminator */ /*表示已为sds分配的内存大小(单位是字节)*/
unsigned char flags; /* 3 lsb of type, 5 unused bits *//* 用一个字节表示当前sdshdr的类型,因为有sdshdr有五种类型,所以至少需要3位来表示。000:sdshdr5,001:sdshdr8,010:sdshdr16,011:sdshdr32,100:sdshdr64。高5位用不到所以都为0。*/
char buf[]; /* sds实际存放的位置 */
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
msb
Significant Bit(最高有效应);lsb Significant Bit(最低有效应). 使用 _attribute_ ((_packed_)) 声明结构体的作用: 让编译器以 紧凑模式 来分配内存,如果不声明该属性,编译器可能会为结构体成员做内存对齐优化,在其中填充空字符,这样就不能保证结构体成员在内存上紧凑相邻的,也不能通过buf数组向低地址偏移一个字节来获取flags字段的值.
char buf[]: 一个没有指定长度的字符数组,这是C语言定义字符数组的一种特殊写法,称为flexible array member,只能定义在一个结构体的最后一个成员,buf起标记作用,表示在flags字段后面就是一个字段数组,程序在为sdshdr分配内存时,他并不占用内存空间.
sizeof(struct sdshdr8)的大小是 (len + alloc + flags)是因为这个struct拥有一个柔性数组成员buf,柔性数组成员是C99之后引入的一个新feature,这里可以通过sizeof在整个struct给出buf变量的偏移量,从而确定buf的位置.
参数说明: len表示sds当前sds的长度(单位是字节),不包括’0’终止符,通过len直接获取字符串长度,不需要扫一遍string,这就是封装sds的理由之一; alloc表示当前为sds分配的大小(单位是字节)(3.2以前的版本用的free是表示还剩free字节可用空间),不包括’0’终止符; flags表示当前sdshdr的类型,声明为char 一共有1个字节(8位),仅用低三位就可以表示所有5种sdshdr类型(详见上文代码注释)。 要判断一个sds属于什么类型的sdshdr,只需 flags&SDS_TYPE_MASK和SDS_TYPE_n比较即可(之所以需要SDS_TYPE_MASK是因为有sdshdr5这个特例,它的高5位不一定为0,参考上面sdshdr5定义里的代码注释)。
对于sdshdr32,sdshdr64也和上面结构一致,差别只在于len和alloc的数据类型不一样而已.
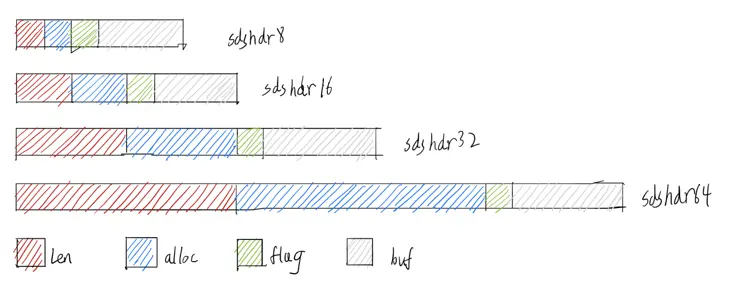
为什么redis费心费力要提供sdshdr5到sdshdr64这五种SDS呢?
我觉着这只能说明Redis作者抠内存抠到机制,牺牲了代码的简洁性换取了每个sds省下来的几个字节的内存空间。从sds初始化方法sdsnew和sdsnewlen中我们就可以看出,redis在新建sds时需要传如初始化长度,然后根据初始化的长度确定用哪种sdshdr,小于2^8长度的用sdshdr8,这样len和alloc只占用两个字节,比较短字符串可能非常多,所以节省下来的内存还是非常可观的,知道了sds的数据结构和设计原理.
/* Create a new sds string with the content specified by the 'init' pointer
* and 'initlen'.
* If NULL is used for 'init' the string is initialized with zero bytes.
* If SDS_NOINIT is used, the buffer is left uninitialized;
*
* The string is always null-termined (all the sds strings are, always) so
* even if you create an sds string with:
*
* mystring = sdsnewlen("abc",3);
*
* You can print the string with printf() as there is an implicit \0 at the
* end of the string. However the string is binary safe and can contain
* \0 characters in the middle, as the length is stored in the sds header. */
sds _sdsnewlen(const void *init, size_t initlen, int trymalloc) {
void *sh;
sds s;
/* 【注】:根据初始化的长度确定用哪种sdshdr
* sdsReqType是一个内部函数,会根据申请的字符串的长度确定对应的sds类型
*(因为sds5只支持长度为2^5的字符串,sds8只支持长度为2^8的字符串,以此类推 */
char type = sdsReqType(initlen);
/* Empty strings are usually created in order to append. Use type 8
* since type 5 is not good at this. */
/* 【注】:这里是一个优化,当initlen为0的时候,意味着要申请一个空sds,
* 空字符串大概率之后会append,但sdshdr5不适合用来append,
* 这个时候sds8会在这方面表现得更好
*/
if (type == SDS_TYPE_5 && initlen == 0) type = SDS_TYPE_8;
int hdrlen = sdsHdrSize(type);
unsigned char *fp; /* flags pointer. */
size_t usable;
assert(initlen + hdrlen + 1 > initlen); /* Catch size_t overflow */
/* 【注】
* s_trymalloc_usable()尝试分配内存,如果失败,则返回NULL。 如果非NULL,则将'* usable'设置为可用大小。
* s_malloc_usable()分配内存或紧急/异常情况。 如果非NULL,则将'* usable'设置为可用大小。
* 具体函数 请查看 (https://github.com/redis/redis/blob/unstable/src/zmalloc.c)*/
sh = trymalloc?
s_trymalloc_usable(hdrlen+initlen+1, &usable) :
s_malloc_usable(hdrlen+initlen+1, &usable);
if (sh == NULL) return NULL;
// SDS_NOINIT=="SDS_NOINIT",如果init是这个字符串,则不对sds进行初始化
if (init==SDS_NOINIT)
init = NULL;
else if (!init)
memset(sh, 0, hdrlen+initlen+1);
/* 【**注意**】:返回的s并不是直接指向sds的指针,而是指向sds中字符串的指针,
* sds的指针还需要根据s和hdrlen计算出来,
* s为sds中buf的起始位置*/
*
s = (char*)sh+hdrlen;
/* fp是sds中flags的指针 */
fp = ((unsigned char*)s)-1;
usable = usable-hdrlen-1;
if (usable > sdsTypeMaxSize(type))
usable = sdsTypeMaxSize(type);
switch(type) {
/* 这个是由sds5的规定确定的,sds5中flags低三位是类型,高五位是字符串长度。
* 所以将initlen偏移三位后,initlen就会移到高五位,
* 再和type或一下,低三位就是type(目前也只有sds5是这样用,所以低三位就只会是0了) */
case SDS_TYPE_5: {
*fp = type | (initlen << SDS_TYPE_BITS);
break;
}
case SDS_TYPE_8: {
SDS_HDR_VAR(8,s);
sh->len = initlen;
sh->alloc = usable;
*fp = type;
break;
}
case SDS_TYPE_16: {
SDS_HDR_VAR(16,s);
sh->len = initlen;
sh->alloc = usable;
*fp = type;
break;
}
case SDS_TYPE_32: {
SDS_HDR_VAR(32,s);
sh->len = initlen;
sh->alloc = usable;
*fp = type;
break;
}
case SDS_TYPE_64: {
SDS_HDR_VAR(64,s);
sh->len = initlen;
sh->alloc = usable;
*fp = type;
break;
}
}
/* 将init字符串的initlen个字节赋值给sds底层char */
if (initlen && init)
memcpy(s, init, initlen);
s[initlen] = '\0';
return s;
}
/* 对 _sdsnewlen 的上层封装。*/
sds sdsnewlen(const void *init, size_t initlen) {
return _sdsnewlen(init, initlen, 0);
}
/* 对 _sdsnewlen 的上层封装。和 sdsnewlen() 的区别是:
* sdstrynewlen() 如果分配内存失败,则返回 null
* sdsnewlen(): 如果分配内存失败,则抛出异常 :zmalloc:尝试分配%zu 字节时内存不足
*
* */
sds sdstrynewlen(const void *init, size_t initlen) {
return _sdsnewlen(init, initlen, 1);
}
流程如下:
- 根据sds的长度判断需要选用sds的类型
- 根据sdshdr的类型用sdsHdrSize函数得到hdrlen(其实就是sizeof(struct sdshdr))
- 为sdshdr分配一个hdrlen + initlen + 1大小的堆内存(+1是为了放置’\0’不计入alloc或len)
- 按参数填充成员len、alloc和type
- 用memcpy给sds复制,并在尾部加上’\0’
- _sdsnewlen()返回的sds指针并不是直接指向sdshdr的地址而是直接指向sdshdr中buf的地址
/* Create an empty (zero length) sds string. Even in this case the string
* always has an implicit null term. */
/* 创建一个空的(零长度)sds字符串。 即使在这种情况下,字符串总是有一个隐含的空项。*/
sds sdsempty(void) {
return sdsnewlen("",0);
}
/* Create a new sds string starting from a null terminated C string. */
/* 创建一个新的SDS字符串从空开始终止的C字符串 */
sds sdsnew(const char *init) {
size_t initlen = (init == NULL) ? 0 : strlen(init);
return sdsnewlen(init, initlen);
}
/* Duplicate an sds string. */
/* 复制一个sds字符串。*/
sds sdsdup(const sds s) {
return sdsnewlen(s, sdslen(s));
}
/* Free an sds string. No operation is performed if 's' is NULL. */
/* 释放一个SDS字符串。 如果“s”为NULL,则不执行任何操作。 */
void sdsfree(sds s) {s
if (s == NULL) return;
s_free((char*)s-sdsHdrSize(s[-1]));
}
二、SDS的使用
由于_sdsnewlen()返回的sds并不止直接指向sdshdr的地址,而是直接指向sdshdr中buf的地址。
好处是:可以兼容C原生字符串。buf其实就是C原生字符串 + 部分空余空间,中间是特殊符号’0’隔开,‘0’有时表示C字符串末尾的符号,这样就是实现了和C原生字符串的兼容,部分C字符串的API可以直接使用。
坏处是:不能直接拿到len和alloc的具体值,但可以间接拿到
假设:我们对sds一无所知,但是我们可以往回退一个字节,由于前一个字节是flag,根据flag可以推断出该sds的len和alloc
static inline size_t sdslen(const sds s) {
unsigned char flags = s[-1]; /* -1 相当于获取到了sdshdr中的flag字段 */
switch(flags&SDS_TYPE_MASK) {
case SDS_TYPE_5:
return SDS_TYPE_5_LEN(flags);
case SDS_TYPE_8:
return SDS_HDR(8,s)->len;
case SDS_TYPE_16:
return SDS_HDR(16,s)->len;
case SDS_TYPE_32:
return SDS_HDR(32,s)->len;
case SDS_TYPE_64:
return SDS_HDR(64,s)->len;
}
return 0;
}
static inline size_t sdsavail(const sds s) {
unsigned char flags = s[-1];
switch(flags&SDS_TYPE_MASK) {
case SDS_TYPE_5: {
return 0;
}
case SDS_TYPE_8: {
SDS_HDR_VAR(8,s);
return sh->alloc - sh->len; /* 宏替换获取到sdshdr中的len */
}
case SDS_TYPE_16: {
SDS_HDR_VAR(16,s);
return sh->alloc - sh->len;
}
case SDS_TYPE_32: {
SDS_HDR_VAR(32,s);
return sh->alloc - sh->len;
}
case SDS_TYPE_64: {
SDS_HDR_VAR(64,s);
return sh->alloc - sh->len;
}
}
return 0;
}
为什么s[-1]可以拿到flag?
- 由于sdshdr结构体类禁用了内存对齐。
- s是指向buf,类型为char,而flags的类型也是char,故s[-1]指向flag,这里的-1就是-1*sizeof(char)
三、SDS扩容
注意:字符串的拼接操作是十分频繁的,在C语言开发中使用char *strcat(char *dest, const char *src)方法将src字符串中的内容拼接到dest字符串的末尾。由于C语言字符串不记录自身的长度,所有strcat方法已经认为用户在执行此函数时已经为dest分配了足够多的内存,足以容纳src字符串中的所有内容,而一旦条件不成立就会产生缓冲区溢出,会把其他数据覆盖带哦。
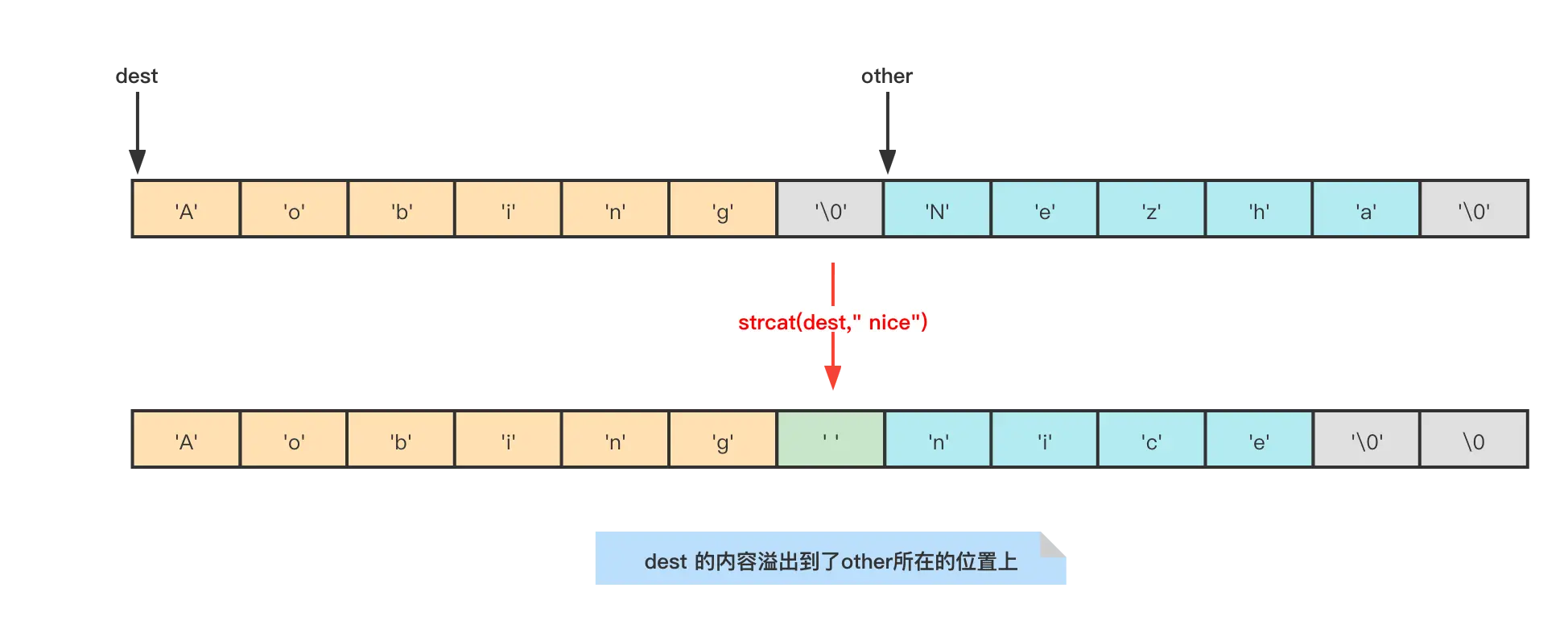
与C语言字符串不同,SDS的自动扩容机制杜绝发生缓冲区溢出的可能性:
当SDS API需要对SDS进行修改时,API会先检查SDS的空间时候满足修改所需的要求,如果不满足于,API会自动将SDS的空间扩展之执行修改所需的大小,然后才执行实际的修改,所以SDS既不需要手动去修改SDS的空间大小,也不会出现缓冲区溢出问题。
sds sdscatsds(sds s, const sds t) {
return sdscatlen(s, t, sdslen(t));
}
/* s: 源字符串
* t: 待拼接字符串
* len: 待拼接字符串长度
*/
sds sdscatlen(sds s, const void *t, size_t len) {
// 获取源字符串长度
size_t curlen = sdslen(s);
// SDS 分配空间(自动扩容机制)
s = sdsMakeRoomFor(s,len);
if (s == NULL) return NULL;
// 将目标字符串拷贝至源字符串末尾
memcpy(s+curlen, t, len);
// 更新 SDS 长度
sdssetlen(s, curlen+len);
// 追加结束符
s[curlen+len] = '\0';
return s;
}
自动扩容机制—sdsMakeRoomFor方法
/* s: 源字符串
* addlen: 新增长度
*/
sds sdsMakeRoomFor(sds s, size_t addlen) {
void *sh, *newsh;
// sdsavail: s->alloc - s->len, 获取 SDS 的剩余长度
size_t avail = sdsavail(s);
size_t len, newlen, reqlen;
// 根据 flags 获取 SDS 的类型 oldtype
char type, oldtype = s[-1] & SDS_TYPE_MASK;
int hdrlen;
size_t usable;
/* Return ASAP if there is enough space left. */
// 剩余空间大于等于新增空间,无需扩容,直接返回源字符串
if (avail >= addlen) return s;
// 获取当前长度
len = sdslen(s);
//
sh = (char*)s-sdsHdrSize(oldtype);
// 新长度
reqlen = newlen = (len+addlen);
// 断言新长度比原长度长,否则终止执行
assert(newlen > len); /* 防止数据溢出 */
// SDS_MAX_PREALLOC = 1024*1024, 即1MB
if (newlen < SDS_MAX_PREALLOC)
// 新增后长度小于 1MB ,则按新长度的两倍扩容
newlen *= 2;
else
// 新增后长度大于 1MB ,则按新长度加上 1MB 扩容
newlen += SDS_MAX_PREALLOC;
// 重新计算 SDS 的类型
type = sdsReqType(newlen);
/* Don't use type 5: the user is appending to the string and type 5 is
* not able to remember empty space, so sdsMakeRoomFor() must be called
* at every appending operation. */
// 不使用 sdshdr5
if (type == SDS_TYPE_5) type = SDS_TYPE_8;
// 获取新的 header 大小
hdrlen = sdsHdrSize(type);
assert(hdrlen + newlen + 1 > reqlen); /* Catch size_t overflow */
if (oldtype==type) {
// 类型没变
// 调用 s_realloc_usable 重新分配可用内存,返回新 SDS 的头部指针
// usable 会被设置为当前分配的大小
newsh = s_realloc_usable(sh, hdrlen+newlen+1, &usable);
if (newsh == NULL) return NULL; // 分配失败直接返回NULL
// 获取指向 buf 的指针
s = (char*)newsh+hdrlen;
} else {
// 类型变化导致 header 的大小也变化,需要向前移动字符串,不能使用 realloc
newsh = s_malloc_usable(hdrlen+newlen+1, &usable);
if (newsh == NULL) return NULL;
// 将原字符串copy至新空间中
memcpy((char*)newsh+hdrlen, s, len+1);
// 释放原字符串内存
s_free(sh);
s = (char*)newsh+hdrlen;
// 更新 SDS 类型
s[-1] = type;
// 设置长度
sdssetlen(s, len);
}
// 获取 buf 总长度(待定)
usable = usable-hdrlen-1;
if (usable > sdsTypeMaxSize(type))
// 若可用空间大于当前类型支持的最大长度则截断
usable = sdsTypeMaxSize(type);
// 设置 buf 总长度
sdssetalloc(s, usable);
return s;
}
- 若SDS中剩余空闲空间avail大于新增内容的长度addlen,这无需扩容。
- 若SDS中剩余空闲空间avail小于或等于新增内容addlen:
若新增后总长度len + addlen < 1M,则按新长度的两倍扩容。
若新增后总长度len + addlen < 1M,则按新长度加上1M扩容。
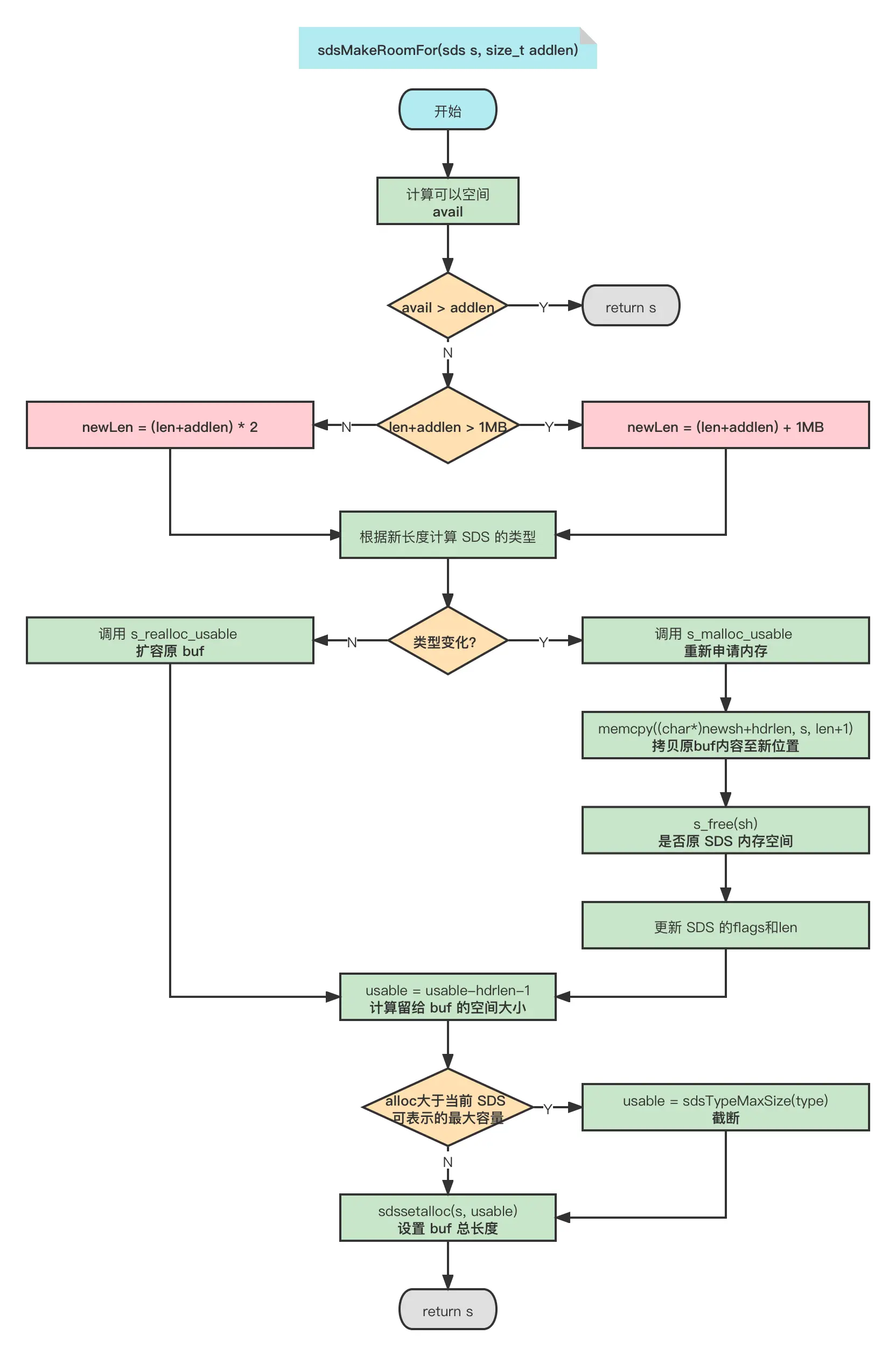
扩容后的SDS不会恰好容纳新增的字符,而是多分配了一些空间(预分配策略),这减少了修改字符串时带来的内存重分配次数
四、内存重分配次数优化
空间预分配策略
因为SDS的空间预分配策略,SDS字符串在增长过程中不会频繁的进行空间分配。通过这种分配策略,SDS将持续增长N次字符串所需要的内存重分配次数从必定N次降低为最多N次。
惰性空间释放机制
空间预分配策略用户优化SDS增长频繁进行空间分配,而惰性释放机制则用于优化SDS字符串缩短时并不立即使用内存分配策略来回收缩短后多出来的空间,而仅仅更新SDS的len属性,多出来的空间公以后使用。
/* sdstrim 方法删除字符串首尾中在 cset 中出现过的字符
* 比如:
* s = sdsnew("AA...AA.a.aa.aHelloWorld :::");
* s = sdstrim(s,"Aa. :");
* printf("%s\n", s);
*
* SDS 变成了 "HelloWorld"
*/
sds sdstrim(sds s, const char *cset) {
char *start, *end, *sp, *ep;
size_t len;
sp = start = s;
ep = end = s+sdslen(s)-1;
// strchr()函数用于查找给定字符串中某一个特定字符
while(sp <= end && strchr(cset, *sp)) sp++;
while(ep > sp && strchr(cset, *ep)) ep--;
len = (sp > ep) ? 0 : ((ep-sp)+1);
if (s != sp) memmove(s, sp, len);
s[len] = '\0';
// 仅仅更新了len
sdssetlen(s,len);
return s;
}
由于没有真正释放空间,也不会导致内存泄露
sds sdsRemoveFreeSpace(sds s) {
void *sh, *newsh;
// 获取类型
char type, oldtype = s[-1] & SDS_TYPE_MASK;
// 获取 header 大小
int hdrlen, oldhdrlen = sdsHdrSize(oldtype);
// 获取原字符串长度
size_t len = sdslen(s);
// 获取可用长度
size_t avail = sdsavail(s);
// 获取指向头部的指针
sh = (char*)s-oldhdrlen;
/* Return ASAP if there is no space left. */
if (avail == 0) return s;
// 查找适合这个字符串长度的最优 SDS 类型
type = sdsReqType(len);
hdrlen = sdsHdrSize(type);
/* 如果类型相同,或者至少仍然需要一个足够大的类型,我们只需 realloc buf即可;
* 否则,说明变化很大,则手动重新分配字符串以使用不同的头文件类型。
*/
if (oldtype==type || type > SDS_TYPE_8) {
newsh = s_realloc(sh, oldhdrlen+len+1);
if (newsh == NULL) return NULL;
s = (char*)newsh+oldhdrlen;
} else {
newsh = s_malloc(hdrlen+len+1);
if (newsh == NULL) return NULL;
memcpy((char*)newsh+hdrlen, s, len+1);
// 释放内存
s_free(sh);
s = (char*)newsh+hdrlen;
s[-1] = type;
sdssetlen(s, len);
}
// 重新设置总长度为len
sdssetalloc(s, len);
return s;
}
Redis 最大的字符串容量512MB,在redis3.x版本中len时使用int修饰的